
Code assistance for boto3, always up to date and in any IDE
If you’re like me and work with the boto3 sdk to automate your Ops, then you probably are familiar with this sight:

No code completion! It’s almost as useful as coding in Notepad, isn’t it? This is one of the major quirks of the boto3 sdk. Due to its dynamic nature, we don’t get code completion like for other libraries like we are used to.
I used to deal with this by going back and forth with the boto3 docs. However, this impacted my productivity by interrupting my flow all the time. I had recently adopted Python as my primary language and had second thoughts on whether it was the right tool to automate my AWS stuff. Eventually, I even became sick of all the back-and-forth.
A couple of weeks ago, I thought enough was enough. I decided to solve the code completion problem so that I never have to worry about it anymore.
But before starting it, a few naysaying questions cropped up in my head:
- How would I find time to support all the APIs that the community and I want?
- Will this work be beneficial to people not using the X IDE?
- With 12 releases of boto3 in the last 15 days, will this become a full time job to continuously update my solution?
Thankfully, I found a lazy programmer’s solution that I could conceive in a weekend. I put up an open source package and released it on PyPI. I announced this on reddit and within a few hours, I saw this:

Looks like a few people are going to find this useful! 🙂
In this post I will describe botostubs, a package that gives you code completion for boto3, all methods in all APIs. It even automatically supports any new boto3 releases.
Read on to learn a couple of less-used facilities in boto3 that made this project possible. You will also learn how I automated myself out of the job of maintaining botostubs by leveraging a simple deployment pipeline on AWS that costs about $0.05 per month to run.
What’s botostubs?
botostubs is a PyPI package, which you can install to give you code completion for any AWS service. You install it in your Python runtime using pip, add “import botostubs” to your scripts and a type hint for your boto3 clients and you’re good to go:

Now, instead of “no suggestions”, your IDE can offer you something more useful like:

The parameters in boto3 are dynamic too so what about them?
With botostubs, you can now get to know which parameters are supported and also which are required or optional:

Much more useful, right? No more back-and-forth with the boto3 docs, yay!
The above is for Intellij/PyCharm but will this work in other IDEs?
Here are a couple of screenshots of botostubs running in Visual Studio Code:

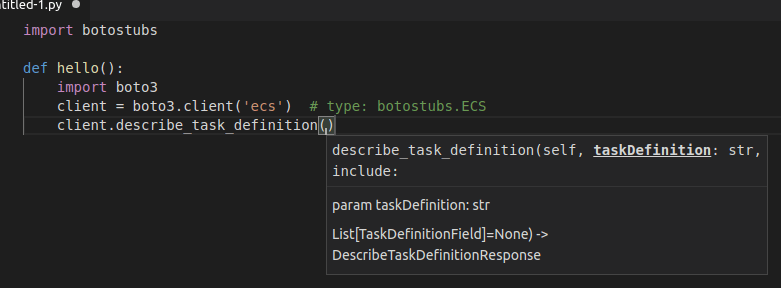
Looks like it works! You should be able to use botostubs in any IDE that supports code completion from python packages.
Why is this an issue in the first place?
As I mentioned before, the boto3 sdk is dynamic, i.e the methods and APIs don’t exist as code. As it says in the guide,
It uses a data-driven approach to generate classes at runtime from JSON description files …
The SDK maintainers do it to be able to enhance the SDK reliably and faster. This is great for the maintainers but terrible for us, the end users of the SDK.
Therefore, we need statically defined classes and methods. Since boto3 doesn’t work that way, we need a separate solution.
How botostubs works
At a high level, we need a way to discover all the available APIs, find out about the method signatures and package them up as classes in a module.
- Get a boto3 session
- Loop over its available clients
- Find out about each client’s operations
- Generate class signatures
- Dump them in a Python module
I didn’t know much about boto3 internals before so I had to do some digging on how to accomplish that. You can use what I’ve learnt here if you’re interested in building tools on top of boto3.
First, about the clients. It’s easy when you already know which API you need, e.g with S3, you write:
client = boto3.client(‘s3’)
But for our situation, we don’t know which ones are there in advance. I could have hardcoded them but I need a scalable and foolproof way. I found out that the way to do that is with a session’s get_available_services() facility.

Tip: Much of what I’ve learnt have been though Intellij’s debugger. Very handy especially when having to deal with dynamic code.

For example, to learn what tricks are involved to get the dynamic code to convert to actual API calls to AWS, you can place a breakpoint in _make_api_call found in boto3’s client.py:

Steps 1 and 2 solved. Next, I had to find out which operations are possible in a scalable fashion. For example, the S3 API supports about 98 operations for listing objects, uploading and downloading them. Coding 98 operations is no fun, so I’m forced to get creative.
Digging deeper, I found out that clients have an internal botocore’s service model that had everything that I was looking for. Through the service model you can find the service documentation, api version, etc.
Side note: botocore is a factored out library that is shared with the AWS CLI. Much of what boto3 is capable is actually powered by botocore.
In particular, we can read the available operation names. E.g the service model for the ACM api returns:

Step 3 was therefore solved with:

Next, we need to know what parameters are available for each operation. In boto parlance, they are called “input shapes”. (Similarly, you can get the output shape if needed) Digging some more in the service model source, I found out that we can get the input shape with the operation model:

This told me the required and optional parameters. The missing part of generating the method signatures was then solved. (I don’t need the method body since I’m generating stubs)
Then it was a matter of generating classes based on the clients and operations above and package them in a Python module.
For any version of boto, I had to run my script, run the twine PyPI utility and it will output a PyPI package that’s up to date with upstream boto3. All of that took about 100 lines of Python code.
Another problem remained to be solved though; with a new boto3 release every time you change your t-shirt, I would need to run it and re-upload to PyPI several times a week. So, wouldn’t this become a maintenance hassle for me?
The deployment pipeline
To solve this problem, I looked to AWS itself. The simplest way I found out was to use their build tool and invoke it on a schedule. What I want is a way to get the latest boto3 version, run the script and upload the artefact to PyPI. All without my intervention.
The relevant AWS services to achieve this is Cloudwatch Events (to trigger other services on a schedule), CodeBuild (managed build service in the cloud) and SNS (for email notifications). This is what the architecture looks like on AWS:

Image generated with viz-cfn
The image above describes the CloudFormation template used to deploy on Github as well as the code.
The AWS Codebuild Project looks like this:


To keep my credentials outside of source control, I also attached a service role to give CodeBuild permissions to write logs and read my PyPI username and password from the Systems Manager parameter store.
I also enabled the build badge feature so that I can show the build status on Github:

For intricate details, check out the buildspec.yml and the project definition.
I want this project to be invoked on a schedule (I chose every 3 days) and I can accomplish that with a Cloudwatch Event Rule:

When the rule gets triggered, I see that my codebuild project does what it needs to do; clone the git repo, generate the stubs and upload to PyPI:

This whole process is done in about 25 seconds. Since this is entirely hands off, I needed some way to be kept in the loop. After the build has run, there’s another Cloudwatch Event which gets triggered for build events on the project. It sends a notification to SNS which in turns sends me an email to let me know if everything went OK:

The build event and notification.

The SNS Topic with an email subscription.
That’s it! But what about my AWS bill? My estimate is that it should be around $0.05 every month. Besides, it will definitely not break the bank, so I’m pretty satisfied with it! Imagine how much it would cost to maintain a build server on your own to accomplish all of that.
What’s with the weird versioning?
You will notice botostubs versions look like this:

It currently follows boto3 releases in the format 0.4.x.y.z. Therefore, if botostubs is currently at 0.4.1.9.61, then it means that it will offer whatever is available in boto3 version 1.9.61. I included the boto version in mine to make it more obvious what version of boto3 that botostubs was generated from but also because PyPI does not allow uploads at the same version number.
Are people using it?
According to pypistats.org, botostubs has been downloaded about 600 times in its initial week after I showed it to the reddit community. So it seems that it was a tool well needed:

Your turn
If this sounds that something that you’ll need, get started by running:
pip install botostubs
Run it and let me know if you have any advice on how to make this better.
Credit
Huge thanks goes to another project called pyboto3 for the original idea. The issues that I had with it was that it was unmaintained and supported legacy Python only. I wouldn’t have known that this would be possible were it not for pyboto3.
Open for contribution
botostubs is an open source project, so feel free to send your pull requests.
A couple of areas where I’ll need some help:
- Support Python < 3.5
- Support boto3 high-level resources (as opposed to just low-level clients)
Summary
In this article, I’ve shared my process for developing botostubs through examining the internals of boto3 and automate its maintenance with a deployment pipeline that handles all the grunt work. If you like it, I would appreciate it if you share it with a fellow Python DevOps engineer
https://pypi.org/project/botostubs/.
I hope you are inspired to find solutions for AWS challenges that are not straightforward and share them with the community.
If you used what you’ve learnt above to build something new, let me know, I’d love to take a look! Tweet me @jeshan25.
About the Author
Jeshan Babooa is an independent software developer from Mauritius. He is passionate about all things infra automation on AWS especially with tools like Cloudformation and Lambda. He is the guy behind LambdaTV, a youtube channel dedicated to teaching serverless on AWS. You can reach him on Twitter @jeshan25.
About the Editors
Ed Anderson is the SRE Manager at RealSelf, organizer of ServerlessDays Seattle, and occasional public speaker. Find him on Twitter at @edyesed.
Jennifer Davis is a Senior Cloud Advocate at Microsoft. Jennifer is the coauthor of Effective DevOps. Previously, she was a principal site reliability engineer at RealSelf, developed cookbooks to simplify building and managing infrastructure at Chef, and built reliable service platforms at Yahoo. She is a core organizer of devopsdays and organizes the Silicon Valley event. She is the founder of CoffeeOps. She has spoken and written about DevOps, Operations, Monitoring, and Automation.


